
储备知识
连续变量与离散变量的定义
连续变量的数值是连接不断的,相邻两值之间可作无限分割,例如,身高、体重、年龄等都是连续变量。年龄一般虽按整数计算,但如严格按出生时间起算,是可以细算到许多位小数的。连续变量的数值要用测量或计算的方法取得。离散变量的各变量值之间都是以整数断开的,如人数、工厂数、机器台数等,都只能按整数计算。离散变量的数值只能用计数的方法取得。
什么是词向量
词向量技术是将词转化成为稠密向量,并且对于相似的词,其对应的词向量也相近。
词的表示
在NLP中,首先需要考虑词如何在计算机中表示。通常,有两种表示方式:one-hot representation和distribution representation。
one-hot representation(离散表示)
一种最简单的词向量方式是 one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量的分量只有一个 1,其他全为 0, 1 的位置对应该词在词典中的位置。 例如:桌子 [0,0,0,1,0,0,0,0,0,……] 。但这种词表示有两个缺点:(1)容易受维数灾难的困扰,尤其是将其用于 Deep Learning 的一些算法时;(2)不能很好地刻画词与词之间的相似性(术语好像叫做“词汇鸿沟”)。但也带来一个好处,就是在高维空间中,很多应用任务线性可分。
distribution representation(分布式表示)
它最早是 Hinton 于 1986 年提出的,可以克服 one-hot representation 的缺点。其基本想法是:通过训练将某种语言中的每一个词映射成一个固定长度的短向量(当然这里的“短”是相对于 one-hot representation 的“长”而言的),将所有这些向量放在一起形成一个词向量空间,而每一向量则为该空间中的一个点,在这个空间上引入“距离”,则可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了。
为更好地理解上述思想,我们来举一个通俗的例子:假设在二维平面上分布有 N 个不同的点,给定其中的某个点,现在想在平面上找到与这个点最相近的一个点,我们是怎么做的呢?首先,建立一个直角坐标系,基于该坐标系,其上的每个点就唯一地对应一个坐标 (x,y);接着引入欧氏距离;最后分别计算这个词与其他 N-1 个词之间的距离,对应最小距离值的那个词便是我们要找的词了。
上面的例子中,坐标(x,y) 的地位相当于词向量,它用来将平面上一个点的位置在数学上作量化。坐标系建立好以后,要得到某个点的坐标是很容易的,然而,在 NLP 任务中,要得到词向量就复杂得多了,而且词向量并不唯一,其质量也依赖于训练语料、训练算法和词向量长度等因素。
分布式表示优点:
(1)词之间存在相似关系:
是词之间存在“距离”概念,这对很多自然语言处理的任务非常有帮助。
(2)包含更多信息:
词向量能够包含更多信息,并且每一维都有特定的含义。在采用one-hot特征时,可以对特征向量进行删减,词向量则不能。
生成词向量
生成词向量的方法有很多,这些方法都依照一个思想:任一词的含义可以用它的周边词来表示。生成词向量的方式可分为:基于统计的方法和基于语言模型(language model)的方法。关于利用深度学习训练词向量的研究 还 有 2008 年 Ronan Collobert 和 Jason weston C&W 方 法、Google 的 Word2Vector 模型、Mikolov 的 RNNLM 模型。这些方法后面咱们慢慢说,今天先分享到这里啦!
word2vec
从深度学习的角度看,假设我们将 NLP 的语言模型看作是一个监督学习问题:即给定上下文词 X,输出中间词 Y,或者给定中间词 X,输出上下文词 Y。基于输入 X 和输出 Y 之间的映射便是语言模型。word2vec 便是一种基于神经网络训练的自然语言模型。word2vec 是谷歌于 2013 年提出的一种 NLP 工具,其特点就是将词汇进行向量化,这样我们就可以定量的分析和挖掘词汇之间的联系。而这种词汇的向量化需要经过神经网络训练得到。
word2vec训练神经网络得到一个关于输入x和输出y之间的语言模型,而我们关注重点并不是说要把这个模型训练的有多好,而是要获取训练好的神经网络权重,这个权重就是我们要拿来对输入词汇x的向量化表示。一旦我们拿到了训练语料所有词汇的词向量,接下来开展NLP分析工作就相对容易一些了。
word2vec一般有两个版本得语言模型。如下图所示:
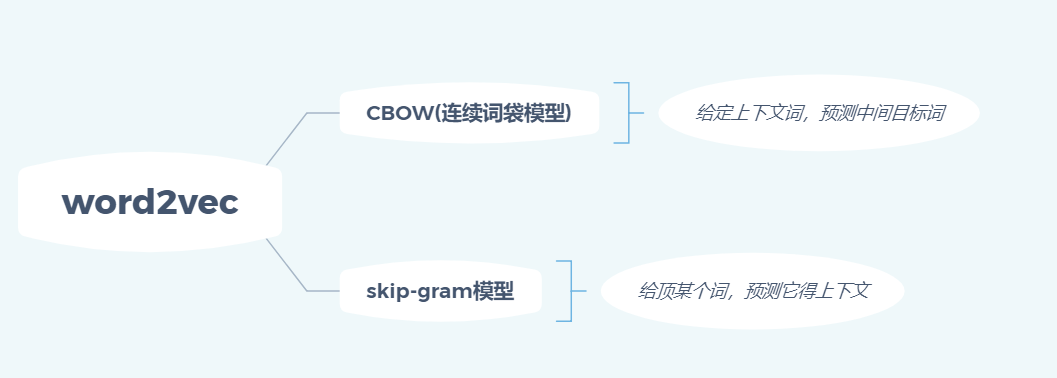
CBOW 模型的应用场景是要根据上下文预测中间词,所以我们的输入便是上下文词,当然原始的单词是无法作为输入的,这里的输入仍然是每个词汇的 one-hot 向量,输出 Y 为给定词汇表中每个词作为目标词的概率。参考大佬 Rong Xin论文中给出的 CBOW 模型的结构图:
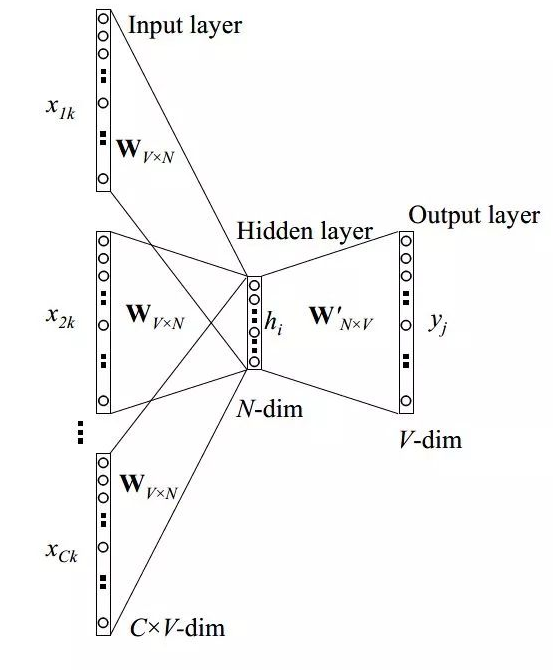
skip-gram 模型的应用场景是要根据中间词预测上下文词,所以我们的输入 X 是任意单词,输出 Y 为给定词汇表中每个词作为上下文词的概率。参考 大佬Rong Xin论文中给出的 skip-gram 模型的结构图:
从 CBOW 和 skip-gram 模型的结构图可以看到,二者除了在输入输出上有所不同外,基本上没有太大区别。将 CBOW 的输入层换成输出层基本上就变成了 skip-gram 模型,二者可以理解为一种互为翻转的关系。
从监督学习的角度来说,word2vec 本质上是一个基于神经网络的多分类问题,当输出词语非常多时,我们则需要一些像分级 Softmax 和负采样之类的 trick 来加速训练。但从自然语言处理的角度来说,word2vec 关注的并不是神经网络模型本身,而是训练之后得到的词汇的向量化表征。这种表征使得最后的词向量维度要远远小于词汇表大小,所以 word2vec 从本质上来说是一种降维操作。我们把数以万计的词汇从高维空间中降维到低维空间中,大大方便了后续的 NLP 分析任务。
注(转自他人总结)
其实这些词向量就是神经网络里的参数,生成词向量的过程就是一个参数更新的过程。那么究竟是什么参数呢?就是这个网络的第一层:将one-hot向量转换成低维词向量的这一层(虽然大家都不称之为一层,但在我看来就是一层),因为word2vec的输入是one-hot。one-hot可看成是1N(N是词总数)的矩阵,与这个系数矩阵(NM, M是word2vec词向量维数)相乘之后就可以得到1M的向量,这个向量就是这个词对应的词向量了。那么对于那个NM的矩阵,每一行就对应了每个单词的词向量。接下来就是进入神经网络,然后通过训练不断更新这个矩阵。这个部分在网上的资料里经常被简略的概括,输出层一般是重点解释的对象,所以需要仔细地理清这个思路。有了这个概念之后再去看word2vec网络具体是怎么实现的,就会容易很多。
Author: Amanda-Zhang
Copyright: All articles in this blog are licensed under CC BY-NC-SA 3.0 unless stating additionally.